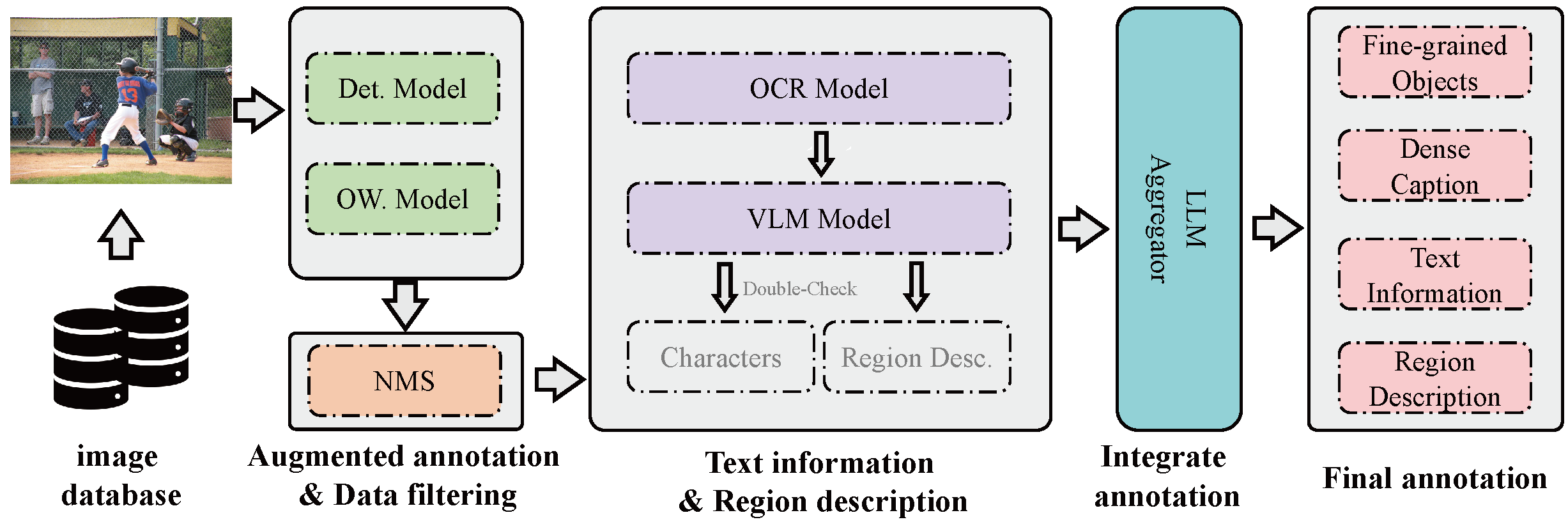
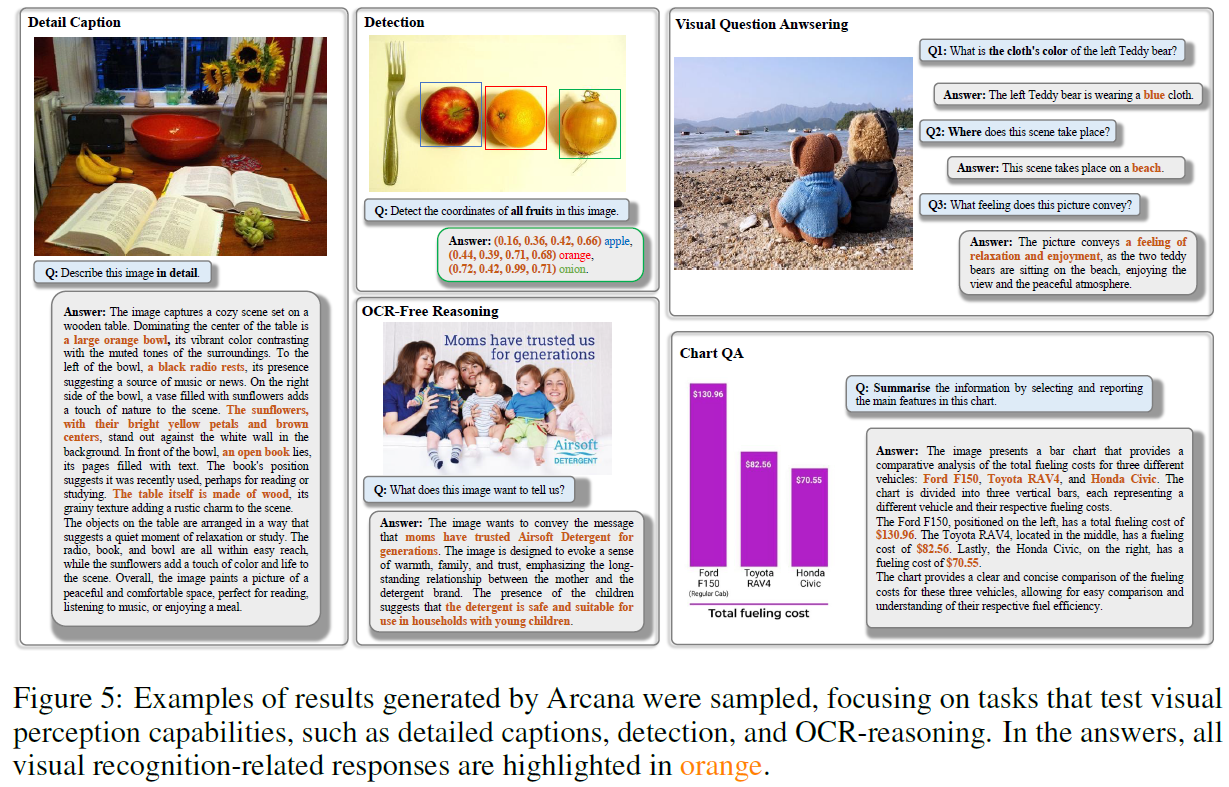
The visual perception capabilities of MLLMs directly impact their performance. It is well-known that the main factors influencing MLLMs' visual perception are data and structure. Arcana aims to enhance the visual perception capabilities of MLLMs by addressing both of these aspects.
On the data side, there is a scarcity of open-source data, and the available multimodal datasets contain limited visual components, preventing MLLMs from gaining sufficient visual perception capabilities from these sources. To this end, we have developed a data engine to annotate multimodal data that ensures a diversity of visual factors. The specific process is as follows:


| File | Type | Description |
|---|---|---|
captions.json |
Image-level captions |
The captions.json file contains 86k conversations about image-level detail/short captions generated by Arcana's data engine. Each element in the JSONL file is formatted as follows:
{
"id": "image_id",
"image": "image_path",,
"conversations":[
{ "from": "human", "value": "<image>\nProvide a detailed description
of the following image" },
{ "from": "gpt", "value": "The scene depicts an airport setting with a
sizable white and green airplane, likely a jumbo jet, stationed on the
runway. The airplane showcases a color scheme of red and green,
highlighting its unique look.."}
]
}
|
region_captions.json |
Region-level captions |
The region_captions.json file contains 86k conversations about region-level captions generated by Arcana's data engine. Each element in the JSONL file is formatted as follows:
{
"id": "image_id",
"image": "image_path",,
"conversations":[
{ "from": "human", "value": "<image>\nProvide a comprehensive
depiction of the area bounded by [0.286, 0.342, 0.658, 0.484]." },
{"from": "gpt", "value": "The area features a large red double-decker
bus with a vibrant advertisement displayed on its side.."},
...
]
}
|
detections.json |
Detections |
The detections.json file contains 86k conversations about object detections generated by Arcana's data engine. Each element in the JSONL file is formatted as follows:
{
"id": "image_id",
"image": "image_path",,
"conversations":[
{ "from": "human", "value": "<image>\nDetect the category encompasses
the region defined by the coordinates [0.324, 0.523, 0.338, 0.538]?" },
{"from": "gpt", "value": "According to the taxonomy, this region is
categorized as a window."},
...
]
}
|
ocrs.json |
OCRs |
The ocrs.json file contains 13k conversations about OCR content in image generated by Arcana's data engine. Each element in the JSONL file is formatted as follows:
{
"id": "image_id",
"image": "image_path",,
"conversations":[
{ "from": "human", "value": "<image>\nProvide the text in
the area bounded by [0.142, 0.863, 0.225, 0.892]." },
{ "from": "gpt", "value": "The text is 2726B2V."},
{ "from": "human", "value": "Tell me where the text 2726B2V is in
this picture." },
{ "from": "gpt", "value": "The text is in [0.142, 0.863, 0.225, 0.892]." }
]
}
|
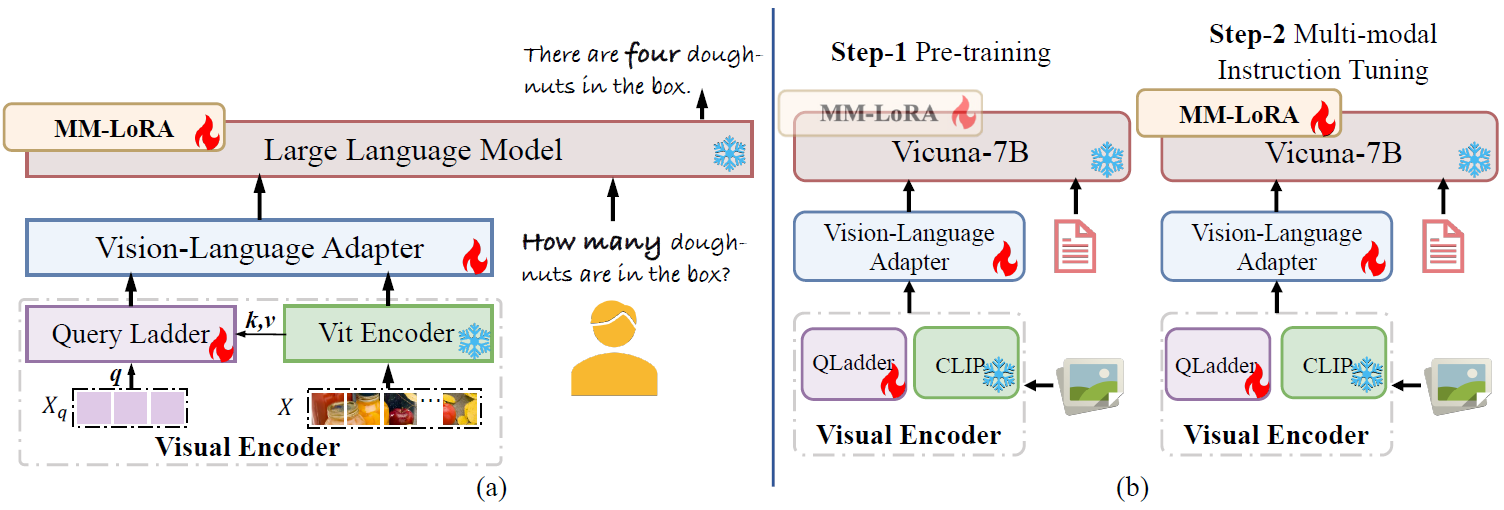
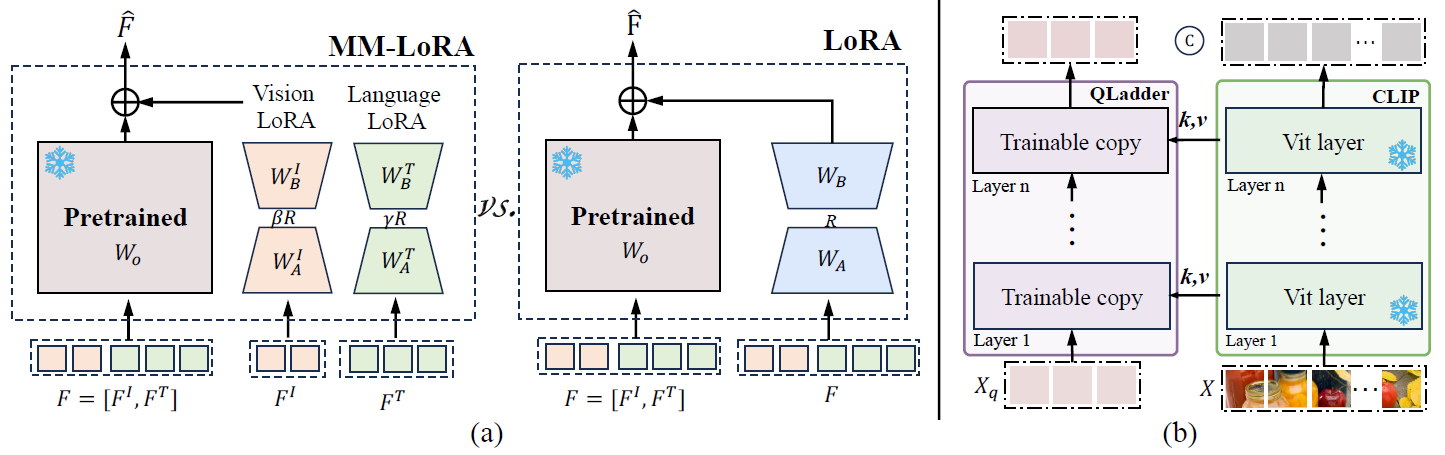
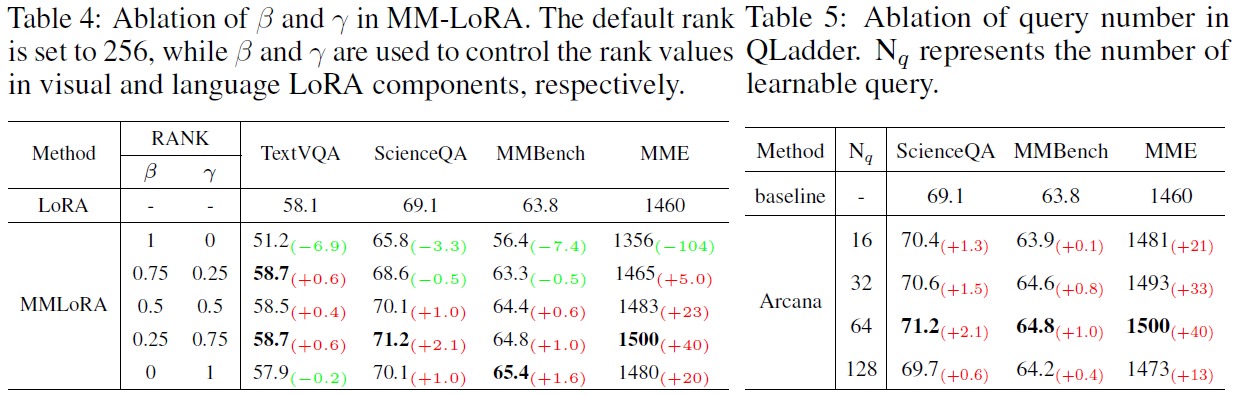
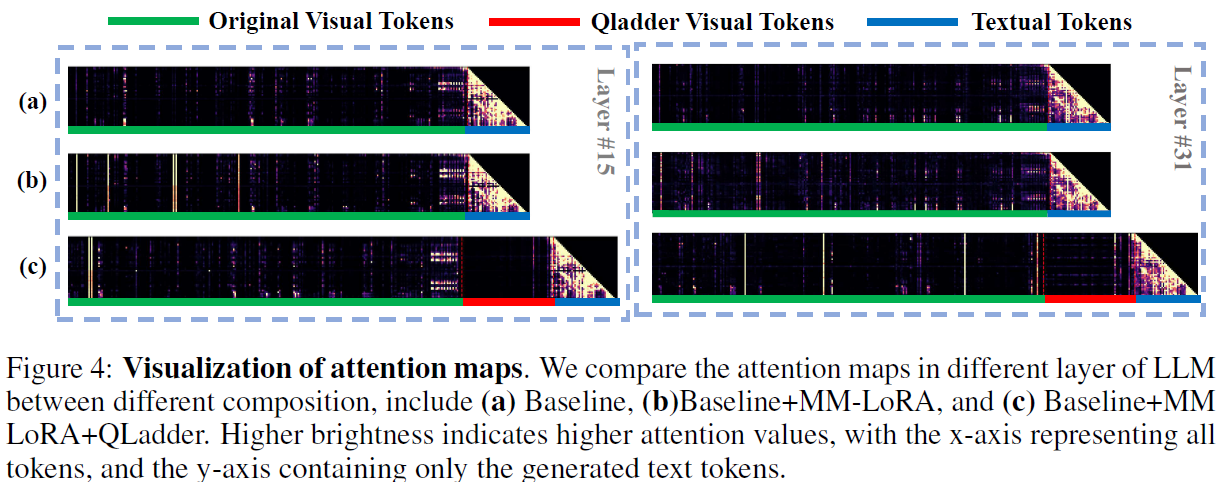
On the structural side, the language-driven decoder couples visual and language modalities within the same space, disregarding their unique characteristics and potentially causing information confusion or blurring. Furthermore, the frozen visual encoder cannot provide robust visual features, and directly fine-tuning it with a small dataset can affect its generalization capabilities. Toward this end, Arcana introduces MM-LoRA, which constructs a multimodal decoder to preserve the unique characteristics of different modalities. We also propose a Query Ladder adapter (QLadder) for the visual encoder, which retains the pre-trained image encoder's capabilities while introducing a small number of visual tokens to significantly enhance the model's ability to learn and represent visual information.
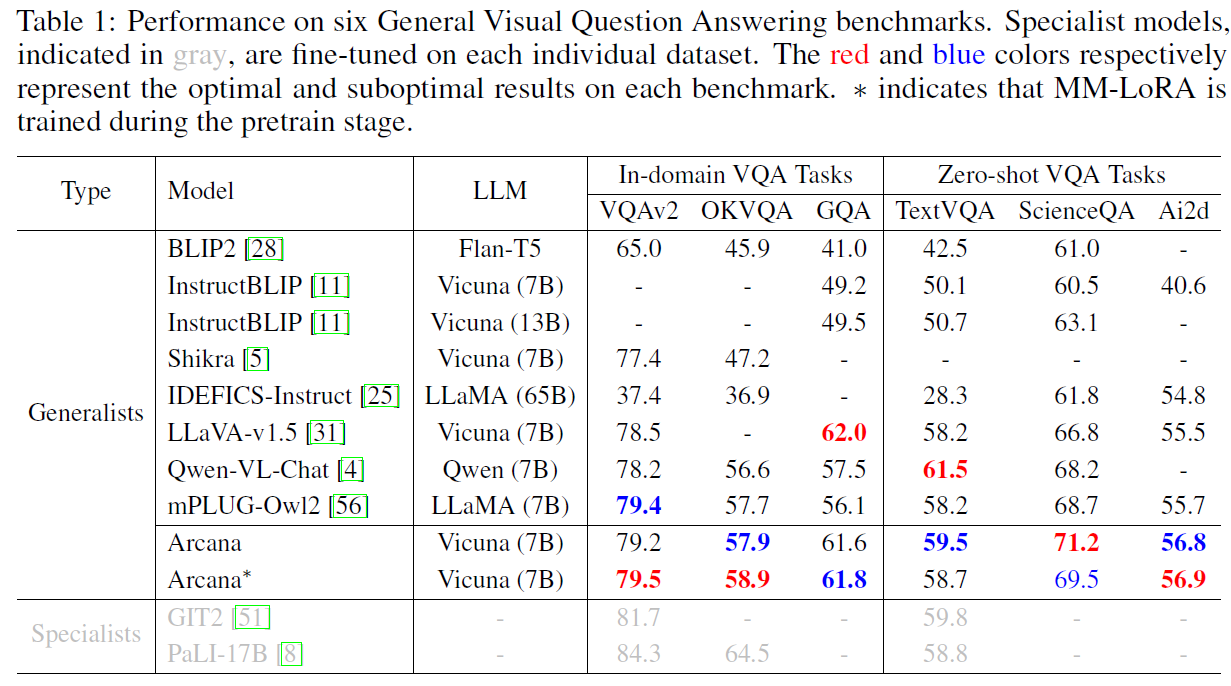
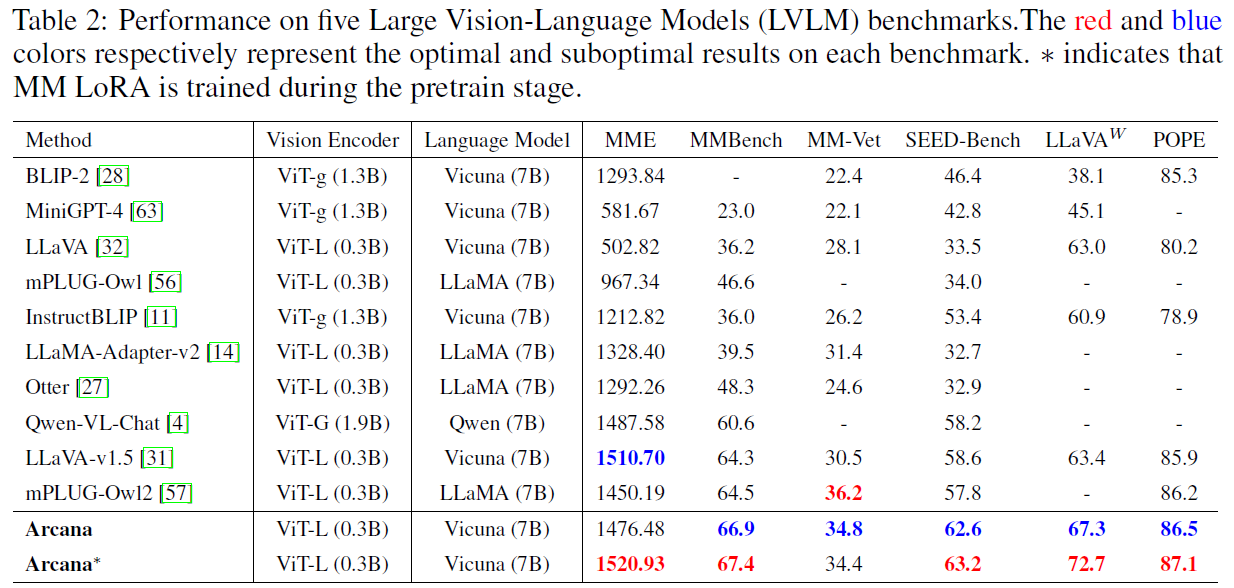
Our Arcana model achieves competitive performance among the exisiting 7B models. To validate the effectiveness of QLadder and MM-LoRA, we designed a series of experiments. Additionally, to ensure fairness, we use only LLAVA-v1.5 data for the ablation experiments.
BibTex Code Here